Introduce Dependencies Among Tasks
Introduction
In the various codelabs dealing with scheduling, you learned how to schedule a hybrid set of tasks consisting of both periodic and aperiodic tasks. In these codelabs, the tasks were assumed to be independent and no task could block any other task.
In this codelab, we address the problem of dependencies among tasks. In multitasking programs, tasks often need to share resources, which must be protected against concurrent access. Such protections are usually implemented using mutexes and Zephyr RTOS is no exception.
In this codelab, you will also experience a situation similar to one that occurred on the Mars Rover Pathfinder in 1997 (see image below). Although you will experience it from a much more comfortable seat than the engineers did in 1997, this example should help to illustrate the need for implementing resource access protocols such as PIP in Zephyr RTOS.
 Source: https://upload.wikimedia.org/wikipedia/commons/7/7f/Mars_Pathfinder_Lander_preparations.jpg
Source: https://upload.wikimedia.org/wikipedia/commons/7/7f/Mars_Pathfinder_Lander_preparations.jpg
{kind=link}
What you’ll build
In this codelab, you will add task dependencies to your CarSystem
application. You will create critical sections that are accessed concurrently by several
tasks and learn how access to these sections impacts the program
and can lead to unexpected behaviors.
What you’ll learn
- How to use Zephyr RTOS mutexes.
- How to create protect critical sections with properly configured mutexes.
- How to configure the PIP mechanism in Zephyr RTOS.
What you’ll need
- You need to have finished the Digging into Zephyr RTOS.
- You need to have completed the Scheduling of periodic tasks codelab and Scheduling of a hybrid set of tasks codelabs.
- You need to have completed the Robust Development Methodologies (I) codelab and the Robust Development Methodologies (II) codelab.
Delivering the Project in Multiple Phases
As documented in the preceding codelab, to deliver the different phases of the project, you must use configuration parameters that correspond to each phase. This codelab relates to PHASE_C of the project, so you must thus add a PHASE_C configuration parameter to your application.
To facilitate the comprehension of task dependencies, it is essential to compile your application with the configuration parameters CONFIG_PHASE_A=y and CONFIG_PHASE_C=y, while ensuring the exclusion of aperiodic tasks generation and servers (e.g., without CONFIG_PHASE_B=y). Thus, your application must compile and behave correctly only with dependent periodic tasks.
Scheduling of Periodic Tasks
In this codelab, we will use the same set of periodic tasks as those used for the project and also used in the preceding codelab.
At this stage, you should have modeled, simulated and observed the schedule of the set of tasks under RM, which should all be identical.
Add Tasks Dependencies
We establish dependencies among tasks by incorporating critical sections protected by mutexes into subsections of code, as depicted below:
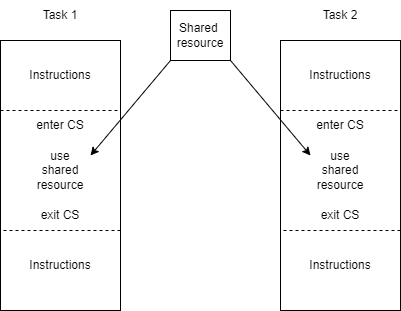
Modify the Existing CarSystem Implementation
To reproduce this pattern programmatically, a simple way is to modify the
PeriodicTaskInfo structure used in the preceding codelabs as follows:
struct SubtaskComputationInfo {
std::chrono::milliseconds _computationTime;
zpp_lib::Mutex* _pMutex;
};
static constexpr uint8_t NbrOfSubTasks = 3;
struct PeriodicTaskInfo {
SubtaskComputationInfo _subTasks[NbrOfSubTasks];
std::chrono::milliseconds _period;
zpp_lib::PreemptableThreadPriority _priority;
const char* _szTaskName;
};
With this modified structure, you can easily define multiple code sections, some of which can be protected by a mutex.
First, modify the initialization of the _taskInfos attribute of the CarSystem class. Then, modify the implementation of the CarSystem::task_method() so that it executes each code section, with or without a critical section.
Initially, use the same task parameters as before - with only one subtask - without a critical section to reproduce the same results.
Adapt the Tasks Parameters to Better Visualize Blocking
The project’s periodic task parameters produce a relatively low CPU utilization factor. These parameters were selected to allow for the easy introduction of sporadic tasks, servers, and background scheduling. However, given the low utilization factor, it is difficult to visualize task dependencies.
To more easily visualize the blocking and priority inversion phenomenon, modify the task parameters as follows:
| Task | Function | WCET [ms] | Period [ms] | \(\Phi\) |
|---|---|---|---|---|
| Engine | Performs car engine checks periodically | 20 | 50 | 0 |
| Display | Displays car information | 20 | 125 | 0 |
| Tire | Performs tire pressure checks | 10 | 200 | 0 |
| Rain | Performs rain detection | 50 | 250 | 0 |
Note that the task periods remain unchanged, but the computation times increase to bring the utilization factor close to the upper bound.
The project task parameters remain unchanged
Do not apply the modification of the task parameters to the code delivered for Project Phase C. You may add a configuration parameter to easily switch task parameters. However, when using CONFIG_PHASE_C=y only, the parameters documented in the project specification should be applied.
However, some of the deliverables of project Phase C are related to demonstrating the blocking and priority inversion phenomenon. Be sure to read the related deliverables carefully while working on this codelab.
Add Critical Sections with Mutual Exclusion
You can create dependencies among tasks by declaring a mutex and defining subtasks for the two tasks that share this mutex. If these tasks share the same critical section, a dependency exists between them, and one could block the other. In this codelab, we will create a dependency between the Engine and Rain tasks using the following parameters:
// Engine subtasks
{._subTasks = { { ._computationTime = 6ms, ._pMutex = nullptr },
{ ._computationTime = 12ms, ._pMutex = &_mutex_ER },
{ ._computationTime = 2ms, ._pMutex = nullptr } },
// Rain subtasks
{._subTasks = { { ._computationTime = 25ms, ._pMutex = nullptr },
{ ._computationTime = 23ms, ._pMutex = &_mutex_ER },
{ ._computationTime = 2ms, ._pMutex = nullptr } },
The _mutex_ER mutex can be created in your CarSystem class using zpp_lib::Mutex or using the Mutex API.
Collect Tasks Statistics with the Modified Parameters
After modifying the CarSystem so that it executes the Engine and Rain subtasks, build your application using -S rtt-tracing and collect task statistics using SEGGER SystemView. You should then observe a similar behavior to that depicted below:

As you can see, at the \(100\ ms\) mark, the Engine task preempts the Rain task. At \(106\ ms\), the Engine task attempts to lock the mutex owned by the Rain task, which blocks the Engine task. At this point, the Rain task inherits the priority of the Engine task and runs again. This demonstrates that the Priority Inheritance Protocol is in use.

Later, at the \(125\ ms\) mark, the Rain task unlocks the mutex. Its original priority is restored, allowing the Engine task to preempts the Rain task again.

This demonstrates how a higher-priority task can be blocked by a lower-priority task when they share resources. While the PIP mechanism prevents unbounded blocking, no protocol can avoid blocking altogether.
Demonstrate Schedulability Under RM and PIP
Once event statistics has been collected, validate that no error is detected by running the Python script using
python csv_marker_parser_with_preemption.py phase_c_mutex_pip.csv --marker 0 --task Engine --period-ms 50 --max-exec-ms 20.3 --marker 1 --task Display --period-ms 125 --max-exec-ms 20.3 --marker 2 --task Tire --period-ms 200 --max-exec-ms 10.2 --marker 3 --task Rain --period-ms 250 --max-exec-ms 50.6 --tolerance-period-start-ms 0.2
You should not detect any error, but even though no error was detected, we still need to demonstrate that the maximum blocking time encountered by the Engine task will not cause it to miss its deadline. Note that this demonstration is part of the deliverables for project Phase C.
Exercice 1 (Deliverable for the Project - Phase C)
- First, demonstrate that the set of periodic tasks with modified task computation times (but without dependencies) is schedulable under RM. You can demonstrate schedulability RM by applying the Liu-Layland or hyperbolic bounds.
- Second, compute the maximum block time for all tasks.
- Then, apply the generalized schedulability test to demonstrate schedulability under RM and PIP.
Demonstrate How a Lower-Priority Task Can Block a Higher-Priority Task without PIP
As demonstrated in the previous section, when a higher-priority task attempts to acquire a mutex owned by a lower-priority task, the lower-priority task inherits the higher-priority task’s priority. This follows the Inheritance Protocol mechanism, which is the default behavior for mutexes in Zephyr RTOS.
This behavior can be modified using the CONFIG_PRIORITY_CEILING configuration parameter. This parameter defines the minimum priority value that a thread will acquire as part of the priority inheritance protocol. Setting this value to a level equal to or lower than the idle thread’s priority level (i.e., the highest possible integer value) will disable the priority inheritance algorithm. By default, the idle thread’s priority is \(15\) and if you add the CONFIG_PRIORITY_CEILING=15 configuration parameter in your {{ prj_conf }} file, this will disable the PIP mechanism.
After rebuilding and running your application, you should observe similar behavior to that depicted below.

Exercice 2 (Deliverable for the Project - Phase C)
- Run your application with PIP deactivated and collect event statistics.
- Take a snapshot of the time diagram like the one in Figure 5. Annotate the diagram to
explain why the
Enginemisses its deadline. Explain why this occurs without PIP. - Run the Python script to analyze the statistics. If violations are detected for a specific task, add the results and comment them.
- Both the annotated snapshot and the statistical analysis results must be added to the
README.mdfile of your project.
Wrap-Up
By the end of this codelab, you should have completed the following steps:
- You modified the
CarSystemapplication to handle multiple code sections that may be protected by a mutex. - You adapted the task parameters for better visualization of the blocking mechanisms.
- You created dependencies between the
EngineandRaintasks. - You computed the maximum blocking times for each task and validated that the set of tasks is schedulable under RM and PIP.
- You demonstrated how disabling the PIP mechanism can affect schedulability.
- You added the deliverables to your project
Phase C, as documented in the codelab.