Exercises related to dependent tasks
NPP and Unnecessary Blocking
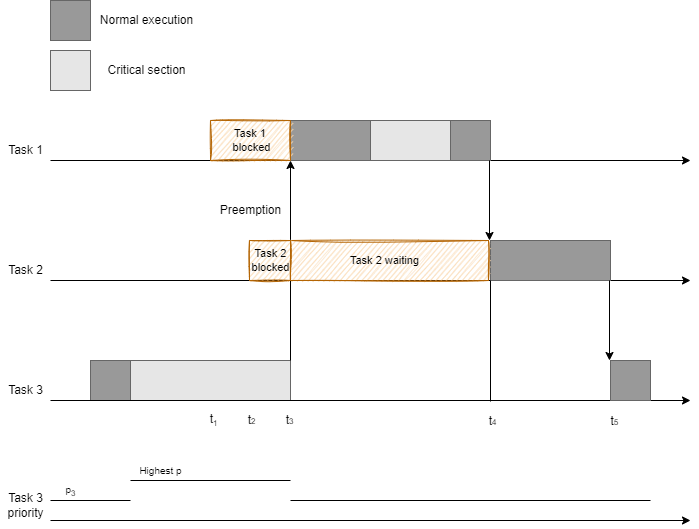
Exercice 1
NPP is simple to implement and it avoids deadlock. But it introduces unnecessary blocking, meaning that a task with higher priority that does not require access to the critical section can be blocked. Illustrate a scenario with 3 tasks where NPP introduces unnecessary blocking.
Solution
In this example, task 2 is unnecessarly blocked by task 3 (because task 3 is set
to the highest priority). Task 1 is also blocked at arrival and not at the time
that it tries to acquire the critical section, which can also create unnecessary blocking.
Maximum Blocking Time Using PIP
Exercice 2
Consider a system with 3 tasks \(\tau_1\), \(\tau_2\), and \(\tau_3\), with decreasing priority. The tasks share 3 resources \(A\), \(B\), and \(C\). Assume that the system is implementing PIP and compute the maximum blocking time \(B_i\) for each task, knowing that the longest access duration of task \(\tau_i\) on resource \(A\), \(B\), and \(C\) is defined as:
| Task | \(A\) | \(B\) | \(C\) |
|---|---|---|---|
| \(\tau_{1}\) | 3 | 0 | 3 |
| \(\tau_{2}\) | 3 | 4 | 0 |
| \(\tau_{3}\) | 4 | 3 | 6 |
Hint: recall the following points:
- Using PIP, a task \(\tau_i\) can be blocked at most once for each lower priority task, i.e. at most for one critical section that can be owned by each lower priority task.
-
A task \(\tau_i\) can be blocked
- through direct blocking: a lower priority task that shares a critical section with \(\tau_i\) owns the critical section.
- through push-through blocking: a medium-priority task is blocked by a low priority task that has inherited a higher priority. It can happen only if a critical section is accessed both by a task with lower priority and by a task with higher priority.
Solution
- In the notation below, \(Z_{j,k}\) denotes the longest critical section of task \(\tau_j\) to access resource \(k\) and \(\delta_{j,k}\) denotes its duration.
- Task \(\tau_1\) can only experience direct blocking since it is the task with the highest priority. The critical sections that can block \(\tau_1\) are \({Z_{2,A}, Z_{3,A}, Z_{3,C}}\). Task \(\tau_1\) can only be blocked once by each lower priority task. The maximum blocking time \(B_1\) is thus \(B_1 = (\delta_{2,A} - 1) + (\delta_{3,C} - 1) = 2 + 5 = 7\).
- Task \(\tau_2\) can be blocked through direct blocking on \({Z_{3,A}, Z_{3,B}}\) and through push-through blocking on \({Z_{3,A}, Z_{3,C}}\). The set of critical sections is thus \({Z_{3,A}, Z_{3,B}, Z_{3,C}}\). Since \(\tau_2\) can only be blocked once by \(\tau_3\), \(B_2 = (\delta_{3,C} - 1) = 5\).
- Task \(\tau_3\) cannot be blocked since it is the task with the lowest priority, hence we have \(B_3 = 0\).
Situation for Maximum Blocking Time Using PIP
Exercice 3
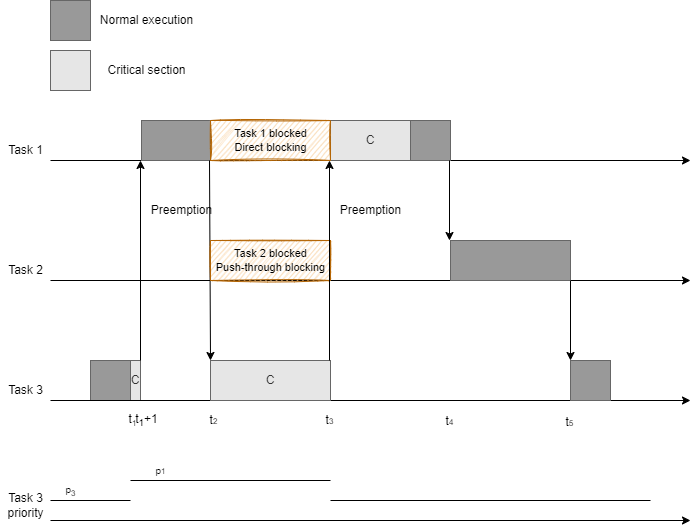
For the task set described in the previous exercise, illustrate the situation in which task \(\tau_2\) experiences its maximum blocking time, when using RM and PIP.
Hint: you must first compute the maximum blocking time of task \(\tau_2\) and reproduce the corresponding situation
Solution
The maximum blocking time for \(\tau_2\) corresponds to a push-through blocking on \(Z_{3,C}\).
Push-through blocking means that task \(\tau_2\) is blocked by task \(\tau_3\), that has inherited priority of \(\tau_1\) (when \(\tau_1\) accesses resource \(C\)). This situation is illustrated below:
Blocking Time Upper Bound using PIP
Exercice 3
The computation of the blocking time upper bound under PIP can be computed with the following algorithm:
Input: Durations \(\delta_{i,k}\) for each task \(\tau_{i}\) and each mutex \(M_{k}\)
Output: \(B_{i}\) for each task \(\tau_{i}\)
Notation: \(Ceiling(M_{k})\) is the priority ceiling of mutex \(M_{k}\).
Notation: \(P_{i}\) is the priority of task \(i\).
Notation: \(\delta_{j,k}\) is the duration of the longest critical section of task \(\tau_{i}\) guarded by mutex \(M_{k}\).
// Assumes tasks are ordered by decreasing priorities
(1) begin
(2) for i := 1 to n − 1 do // for each task
(3) \(B^{l}_{i}\) := 0;
(4) for j := i + 1 to n do // for each lower priority task
(5) \(D_{max}\) := 0;
(6) for k := 1 to m do // for each semaphore
(7) if (\(Ceiling(M_{k})\) ≥ \(P_{i}\)) and (\(\delta_{j,k}\) > \(D_{max}\)) do
(8) \(D_{max}\) := \(\delta_{j,k}\);
(9) end
(10) end
(11) if (\(D_{max}\) > 0) do
(11) \(B^{l}_{i}\) := \(B^{l}_{i}\) + \(D_{max}\);
(12) end
(12) end
(13) \(B^{s}_{i}\) := 0;
(14) for k := 1 to m do // for each semaphore
(15) \(D_{max}\) := 0;
(16) for j := i + 1 to n do // for each lower priority task
(17) if (\(Ceiling(M_{k})\) ≥ \(P_{i}\)) and (\(\delta_{j,k}\) > \(D_{max}\)) do
(18) \(D_{max}\) := \(\delta_{j,k}\);
(19) end
(20) end
(11) if (\(D_{max}\) > 0) do
(21) \(B^{s}_{i}\) := \(B^{s}_{i}\) + \(D_{max}\);
(12) end
(22) end
(23) \(B_{i}\) := min(\(B^{l}_{i}\), \(B^{s}_{i}\));
(24) end
(25) \(B_{n}\) := 0;
(26) end
Given four tasks \(\tau_{i}\) that share three mutexes \(M_{k}\) with durations \(\delta_{i,k}\),
| Task | \(\delta_{i,1}\) | \(\delta_{i,2}\) | \(\delta_{i,3}\) |
|---|---|---|---|
| \(\tau_{1}\) | 1 | 2 | 0 |
| \(\tau_{2}\) | 0 | 9 | 3 |
| \(\tau_{3}\) | 8 | 7 | 0 |
| \(\tau_{4}\) | 6 | 5 | 4 |
and the corresponding priority ceiling for each mutex,
| Semaphore | Priority ceiling |
|---|---|
| \(M_{1}\) | \(p_{1}\) |
| \(M_{2}\) | \(p_{1}\) |
| \(M_{3}\) | \(p_{2}\) |
compute the upper bound of the blocking time \(B_{i}\) for each task \(\tau_{i}\).
Note that a value of \(0\) in the table above means that the corresponding task is not using the mutex.
Solution
(2) i := 1
(3) \(B^{l}_{1}\) := 0
(4) j := 2
(5) \(D_{max}\) := 0
(6) k := 1
(7) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{2,1}\) == 0
(6) k := 2
(7) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{2,2}\) == 9
(8) \(D_{max}\) := 9
(6) k := 3
(7) Ceiling(\(M_{3}\)) == \(p_{2}\), \(\delta_{2,3}\) == 3
(11) \(B^{l}_{1}\) := 0 + 9 - 1 := 8
(4) j := 3
(5) \(D_{max}\) := 0
(6) k := 1
(7) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{3,1}\) == 8
(8) \(D_{max}\) := 8
(6) k := 2
(7) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{3,2}\) == 7
(6) k := 3
(7) Ceiling(\(M_{3}\)) == \(p_{2}\), \(\delta_{3,3}\) == 3
(11) \(B^{l}_{1}\) := 8 + 8 - 1 := 15
(4) j := 4
(5) \(D_{max}\) := 0
(6) k := 1
(7) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{4,1}\) == 6
(8) \(D_{max}\) := 6
(6) k := 2
(7) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{4,2}\) == 5
(6) k := 3
(7) Ceiling(\(M_{3}\)) == \(p_{2}\), \(\delta_{4,3}\) == 4
(11) \(B^{l}_{1}\) := 15 + 6 - 1 := 20
(13) \(B^{s}_{i}\) := 0
(14) k := 1
(15) \(D_{max}\) := 0
(16) j := 2
(17) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{2,1}\) == 0
(16) j := 3
(17) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{3,1}\) == 8
(18) \(D_{max}\) := 8
(16) j := 4
(17) Ceiling(\(M_{1}\)) == \(p_{1}\), \(\delta_{4,1}\) == 6
(21) \(B^{s}_{1}\) := 0 + 8 - 1 := 7
(14) k := 2
(15) \(D_{max}\) := 0
(16) j := 2
(17) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{2,2}\) == 9
(18) \(D_{max}\) := 9
(16) j := 3
(17) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{3,2}\) == 7
(16) j := 4
(17) Ceiling(\(M_{2}\)) == \(p_{1}\), \(\delta_{4,2}\) == 5
(21) \(B^{s}_{1}\) := 7 + 9 - 1 := 15
(14) k := 3
(15) \(D_{max}\) := 0
(17) Ceiling(\(M_{3}\)) == \(p_{2}\) so \(D_{max}\) := 0
(23) \(B_{1}\) := min(\(B^{l}_{1}\), \(B^{s}_{1}\)) := 15
Run the same for \(B_{2}\)
(2) i := 2
(11) \(B^{l}_{2}\) := 7 + 5 := 12
(21) \(B^{s}_{2}\) := 7 + 6 + 3 := 16
(23) \(B_{2}\) := min(\(B^{l}_{2}\), \(B^{s}_{2}\)) := 12
Run the same for \(B_{3}\)
(2) i := 3
(11) \(B^{l}_{3}\) := 5 := 5
(21) \(B^{s}_{3}\) := 5 + 4 + 3 := 12
(23) \(B_{3}\) := min(\(B^{l}_{3}\), \(B^{s}_{3}\)) := 5
And we have \(B_{4}\) := 0 // the task with the lowest priority cannot be blocked
Schedulability Analysis for dependent tasks
Exercice 4
Consider the following task set with their computing time, period and blocking time:
| Task | \(C_{i}\) | \(T_{i}\) | \(B_{i}\) |
|---|---|---|---|
| \(\tau_{1}\) | 4 | 10 | 5 |
| \(\tau_{2}\) | 3 | 15 | 3 |
| \(\tau_{3}\) | 3 | 20 | 0 |
Note that the blocking time of the task with the lowest priority is 0 in all cases. Using the generalized schedulability test, validate the schedulability of this task set.
Solution
The generalized schedulability test is \(\forall i\), \(1 <= i <= n\), \(\sum_{k=1}^{i-1}\frac{C_{k}}{T_{k}} + \frac{C_{i} + B_{i}}{T_{i}} <= i(2^{\frac{1}{i}} - 1)\)
\(i=1\), \(\frac{C_{1} + B_{1}}{T_{1}} = \frac{9}{10} < 1\)
\(i=2\), \(\frac{C_{1}}{T_{1}} + \frac{C_{2} + B_{2}}{T_{2}} = \frac{4}{10} + \frac{6}{15} = \frac{4}{5} < 0.83\)
\(i=3\), \(\frac{C_{1}}{T_{1}} + \frac{C_{2}}{T_{2}} + \frac{C_{3} + B_{3}}{T_{3}} = \frac{4}{10} + \frac{3}{15} + \frac{3}{20} = \frac{3}{4} < 0.77\)
Since this condition is sufficient, we can conclude that the set of tasks is schedulable.
For the sake of demonstration, we can also apply the generalized hyperbolic test.
The generalized hyperbolic test is \(\forall i\), \(1 <= i <= n\), \(\prod_{k=1}^{i-1}(\frac{C_{k}}{T_{k}} + 1)(\frac{C_{i} + B_{i}}{T_{i}} + 1) <= 2\)
\(i=1\), \((\frac{C_{1} + B_{1}}{T_{1}} + 1) = \frac{9}{10} + 1 < 2\)
\(i=2\), \((\frac{C_{1}}{T_{1}} + 1)(\frac{C_{2} + B_{2}}{T_{2}} + 1) = (\frac{14}{10})(\frac{21}{15}) = \frac{294}{150} < 2\)
\(i=3\), \((\frac{C_{1}}{T_{1}} + 1)(\frac{C_{2}}{T_{2}} + 1)(\frac{C_{3} + B_{3}}{T_{3}} + 1) = (\frac{14}{10})(\frac{18}{15})(\frac{23}{20}) = \frac{5796}{3000} < 2\)
Since this condition is sufficient, we can conclude as expected that the set of tasks is schedulable.
PIP Implementation in Zephyr RTOS: data structures
Exercice 5
To implement the Priority Inheritance Protocol, the following changes are required in the kernel:
- The nominal/original and active priority of each thread must be stored.
- Inheritance: Each mutex keeps track of the thread holding the mutex.
- Transitivity: Each thread keeps track of the mutex in which it is blocked.
The k_thread and k_mutex data structures are defined in the zephyr/include/zephyr/kernel.h file.
Examine the data structures and document how the support for PIP is implemented.
Solution
-
The nominal/original and active priority of each thread must be stored:
Thek_threaddata structure contains an internal_thread_basedata structure. This data structure contains anunionstructure for the scheduler lock count and the thread priority.Sounion { struct { ... /* Little Endian */ int8_t prio; uint8_t sched_locked; ... }; uint16_t preempt; };k_thread._thread_base.priostores the active thread priority. -
The
k_mutexdata structure contains aowner_orig_priointeger value. This value is used in thez_impl_k_mutex_lock()andz_impl_k_mutex_unlock()functions to store and restore the original thread priority.struct k_mutex { ... /** Original thread priority */ int owner_orig_prio; ... } -
Inheritance: Each mutex keeps track of the thread holding the mutex. The
k_mutexdata structure contains a pointer to the thread holding the mutexstruct k_mutex { ... /** Mutex owner */ struct k_thread *owner; ... } -
Transitivity: Each thread keeps track of the mutex in which it is blocked The
k_mutexdata structure contains a_wait_q_tfield that stores all threads waiting on it. The mutex wait queue is passed as argument to thez_pend_curr()function called fromz_impl_k_mutex_lock(). This function adds the current thread to the waiting queue of the mutex.struct k_mutex { ... /** Mutex wait queue */ _wait_q_t wait_q; ... }
PIP Implementation in Zephyr RTOS: Mutex lock and unlock
Exercice 6
Implementation of z_impl_k_mutex_lock() to support PIP:
- If the mutex is free upon lock, it becomes locked and the mutex keeps track of the thread locking the mutex.
- If the mutex is locked upon lock, the priority of the thread locking it is changed to the priority of the task calling lock.
- PIP can be disabled by setting
CONFIG_PRIORITY_CEILINGto the lowest possible priority.
The z_impl_k_mutex_lock() function is defined in the zephyr/kernel/mutex.c file.
Examine the code and document how the support for PIP is implemented.
Solution
- When the mutex is free upon lock, it becomes locked and the mutex keeps track of the thread locking the mutex:
// Check if Mutex is not locked if (likely((mutex->lock_count == 0U) || (mutex->owner == _current))) { ... mutex->lock_count++; mutex->owner = _current; ... } - When the mutex is locked upon lock, the priority of the owner thread is changed to the one of the calling thread:
... new_prio = new_prio_for_inheritance(_current->base.prio, mutex->owner->base.prio); LOG_DBG("adjusting prio up on mutex %p", mutex); if (z_is_prio_higher(new_prio, mutex->owner->base.prio)) { resched = adjust_owner_prio(mutex, new_prio); } ... - In the
new_prio_for_inheritance()function, the new priority is compared toCONFIG_PRIORITY_CEILINGusing thez_get_new_prio_with_ceiling()function. The new priority is set as the maximum of the priority of the thread attempting to lock the mutex andCONFIG_PRIORITY_CEILING. Note that the default value ofCONFIG_PRIORITY_CEILINGis-128.
Exercice 7
Implementation of z_impl_k_mutex_unlock() to support PIP:
- If no thread is blocked on the mutex, then simply unlock the Mutex.
- If one or more threads are blocked on the mutex, then the highest-priority thread is awakened and is stored as owner of the mutex. The priority of the thread unlocking the mutex is updated.
The z_impl_k_mutex_unlock() function is defined in the zephyr/kernel/mutex.c file.
Examine the code and document how the support for PIP is implemented.
Solution
- Since the mutex implementation may be reentrant/recursive, the lock count is first checked to be > 0. If it is
greater than 1, it is simply decremented and the function returns:
... __ASSERT_NO_MSG(mutex->lock_count > 0U); ... if (mutex->lock_count > 1U) { mutex->lock_count--; goto k_mutex_unlock_return; } ... -
If the lock count is 1, it means that this thread releases the mutex.
- The priority of the thread unlocking the mutex is adjusted to its original value:
adjust_owner_prio(mutex, mutex->owner_orig_prio); - The new owner of the mutex is extracted from the waiting queue (that is priority-based)
/* Get the new owner, if any */ new_owner = z_unpend_first_thread(&mutex->wait_q); - If the waiting list was empty, meaning that no thread was waiting for this mutex, then the owner of the mutex is set to
NULL, the lock count is set to0, and the function returns. - If another thread was waiting for the mutex, then the highest-priority thread extracted from the waiting queue is awakened and is stored as owner of the mutex. The original priority of the mutex owning thread is updated.
mutex->owner = new_owner; ... if (unlikely(new_owner != NULL)) { /* * new owner is already of higher or equal prio than first * waiter since the wait queue is priority-based: no need to * adjust its priority */ mutex->owner_orig_prio = new_owner->base.prio; arch_thread_return_value_set(new_owner, 0); z_ready_thread(new_owner); z_reschedule(&lock, key); } else { mutex->lock_count = 0U; k_spin_unlock(&lock, key); }
- The priority of the thread unlocking the mutex is adjusted to its original value: